Scaling Synthetic Task Generation for Agents via Exploration
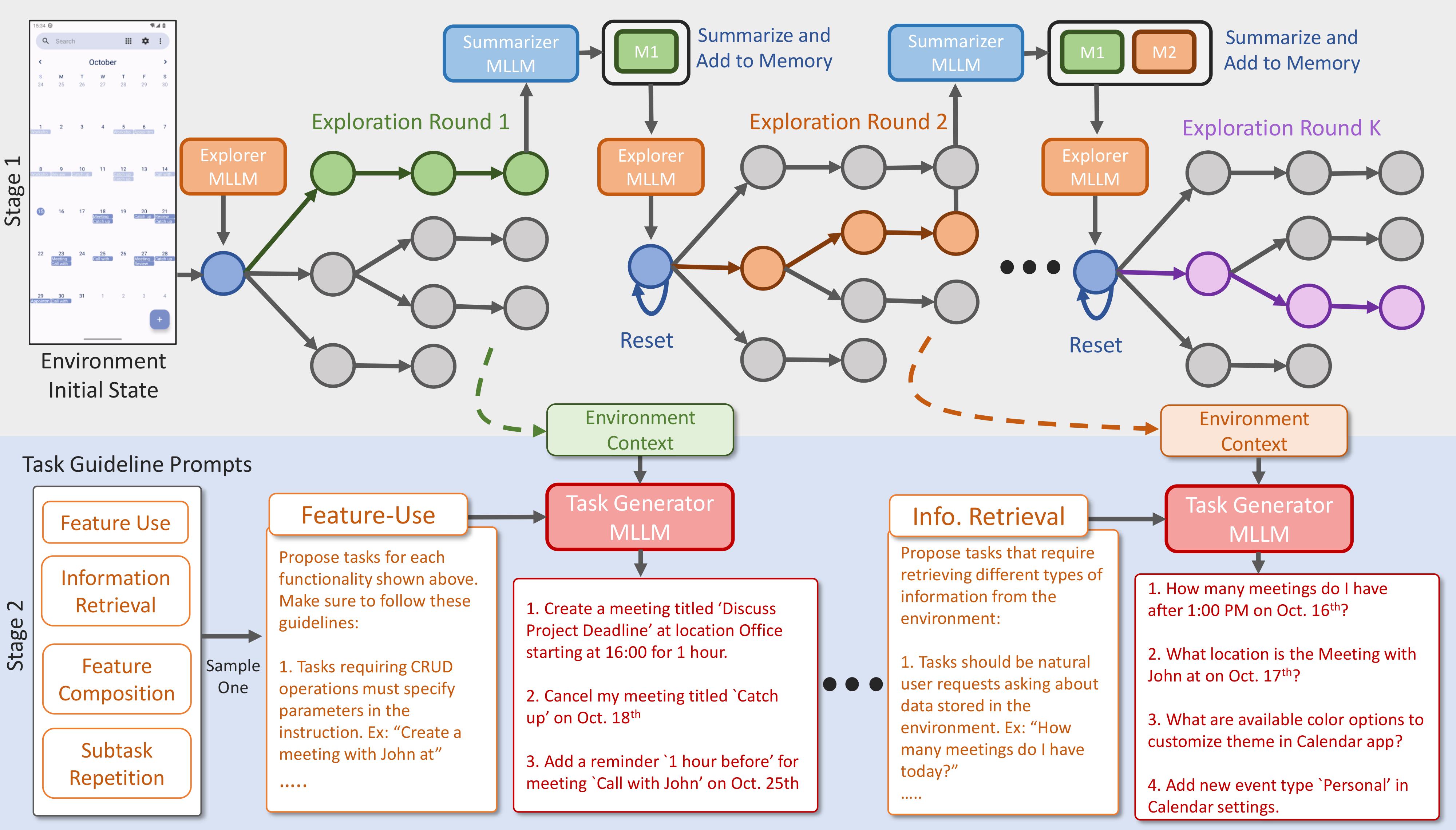
AutoPlay generates large-scale, diverse and verifiable tasks for scaling supervision for MLLM agents. In stage 1 (top), AutoPlay covers the environment states through a MLLM exploration policy that tracks seen states via a memory module. Next, stage 2 (bottom) uses these exploratory trajectories and task guideline prompts as context for proposing tasks. The guidelines help enforce task diversity and the exploration trajectories uncover environment features and content relevant for proposing tasks.
Abstract
Post-Training Multimodal Large Language Models (MLLMs) to build interactive agents holds promise across domains such as computer-use, web navigation, and robotics. A key challenge in scaling such post-training is lack of high-quality downstream agentic task datasets with tasks that are diverse, feasible, and verifiable. Existing approaches for task generation rely heavily on human annotation or prompting MLLM with limited downstream environment information, which is either costly or poorly scalable as it yield tasks with limited coverage. To remedy this, we present AutoPlay, a scalable pipeline for task generation that explicitly explores interactive environments to discover possible interactions and current state information to synthesize environment-grounded tasks. AutoPlay operates in two stages: (i) an exploration phase, where an MLLM explorer agent systematically uncovers novel environment states and functionalities, and (ii) a task generation phase, where a task generator leverages exploration trajectories and a set of task guideline prompts as context to synthesize diverse, executable, and verifiable tasks. We show AutoPlay generates 20k tasks across 20 Android applications and 10k tasks across 13 Ubuntu applications to train mobile-use and computer-use agents. AutoPlay generated tasks enable large-scale task demonstration synthesis without human annotation by employing an MLLM task executor and verifier. This data enables training MLLM-based UI agents that improve success rates up to 20.0% on mobile-use and 10.9% on computer-use scenarios. In addition, AutoPlay generated tasks combined with MLLM verifier-based rewards enable scaling reinforcement learning training of UI agents, leading to an additional 5.7% gain. coverage. These results establish AutoPlay as a scalable approach for post-training capable MLLM agents reducing reliance on human annotation.
Read more in the paper.
Approach
We introduce AutoPlay an approach for scalable task generation with a focus on task coverage, feasibility, and verifiability. Our method, depicted in Fig.1, incorporates two phases of exploration and task generation. First, in Environment Exploration phase, an MLLM explorer agent equipped with memory is prompted to exhaustively explore an increasing number of novel environment states (top of Fig. 1). Such exploratory trajectories are intended to discover the accessible functionalities and content of the environment. Next, in Task Generation phase, a task generator MLLM uses exploration trajectories as environment context to produce diverse environment-grounded tasks based on a set of task guideline prompts which describe desired task properties (bottom of Fig. 1). For instance, a task guideline prompt for Feature-Use tasks would encourage generation of tasks that require doing diverse create, edit, of delete operations on entities in the environment. We present an example of the exploration trajectory collected by AutoPlay and the corresponding tasks synthesized using task generator grounded in the state of the environment in Fig. 2 below.
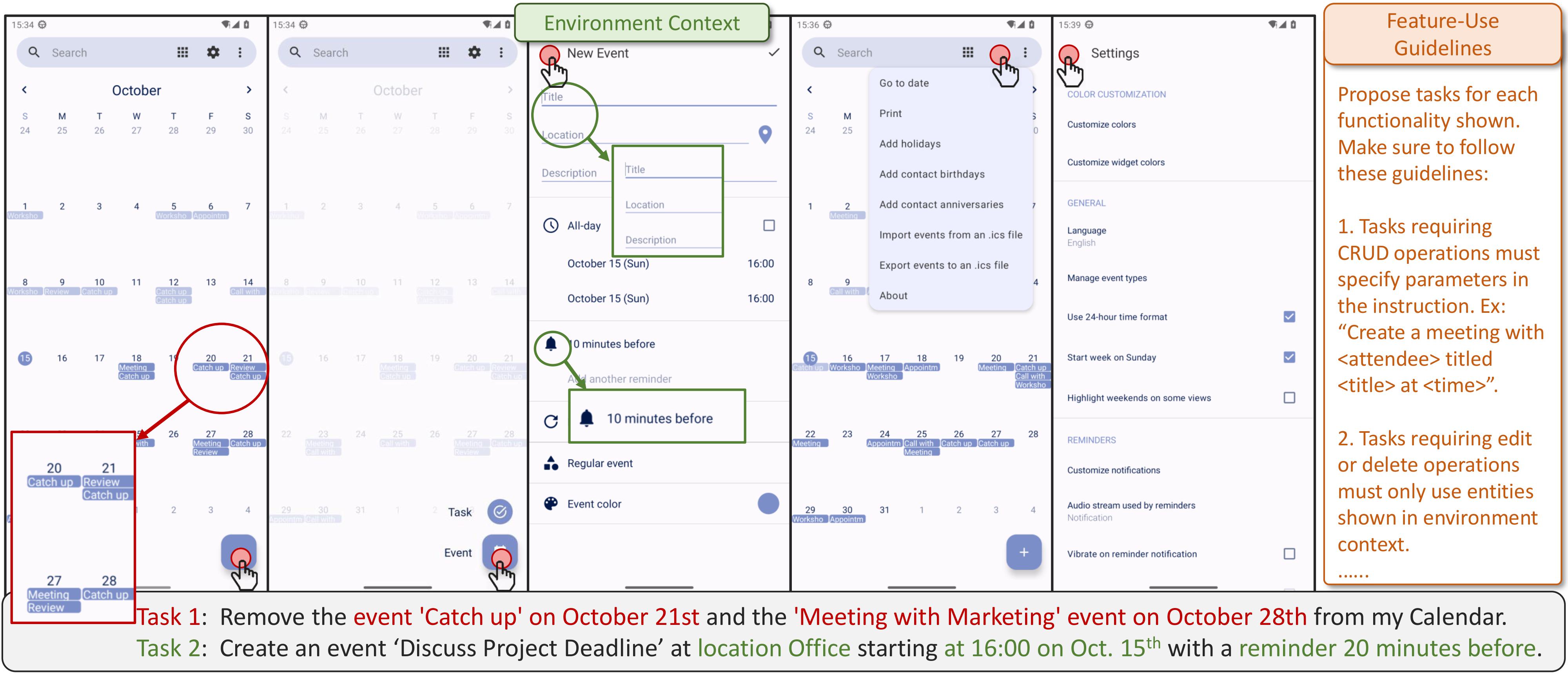
Fig 2. Task Example Example of task generation based on an environment context, represented as a set of screenshots and interactions, and a set of task guidelines. AutoPlay uses presences of events in the calendar together with guidance of using entities in the context, such as names and dates, to produce Task 1. Similarly, showing the event creation form in the context, coupled with guidance to use these fields as task parameters, results in Task 2.
Exploration Trajectories and Task Examples
Fig 3. Qualitative Examples of three exploration trajectories gathered during Exploration Phase. Each exploration trajectory provide coverage over novel environment states and functionalities of the application, as illustrated in the demonstrations. Next, using observations from each exploration trajectory as environment context combined with task guideline prompts, the MLLM task generator synthesizes diverse and feasible tasks for each trajectory during Task Generation phase. We present three sample tasks generated for each trajectory below the corresponding demonstration.
Results
We demonstrate that AutoPlay enables scaling generation of synthetic tasks for UI agents, that are feasible, diverse and grounded in environment state and functionality all without human annotations. The resulting high-quality tasks enable scaling of supervised finetuning (SFT) and reinforcement learning (RL) for post-training MLLMs as capable UI agents.
AutoPlay achieves competitive results with Proprietary Baselines trained on human data: Tab. 1 shows that AutoPlay outperforms strong UI agent models such as UI-TARS-1.5, which was trained on large-scale human-annotated GUI data, by 10.2% at the 7B scale and 13.7% at the 72B scale on AndroidWorld. On OSWorld, AutoPlay-72B surpasses the two-stage training pipeline used in AguVis-72B, which leverages both grounding data and human-annotated GUI navigation data, by 5.0% in success rate. Although UI-TARS-2 230B and Seed-VL-1.5 achieve higher performance on AndroidWorld, they rely on substantially larger mixtures of expert models. Similarly, UI-TARS outperforms AutoPlay on OSWorld, likely due to its use of curated, human-labeled UI data—whereas AutoPlay autonomously explores, proposes tasks, and collects data without human supervision.
AutoPlay in conjunction with MLLM task verifier enables scaling RL training: In Tab. 1 we also highlight that it is feasible to perform RL training on the AutoPlay generated tasks in conjunction with the MLLM task verifier. This enables RL training on AutoPlay generated tasks without requiring any human annotation or environment feedback. RL allows training on all AutoPlay tasks, even those the executor is not able to solve, enabling a scalable way to train UI agents. We see a 5.7% gain in AndroidWorld. With RL training, the AutoPlay-3B model performs similarly to the AutoPlay-7B model trained with just SFT (39.9% versus 40.1% success rate).
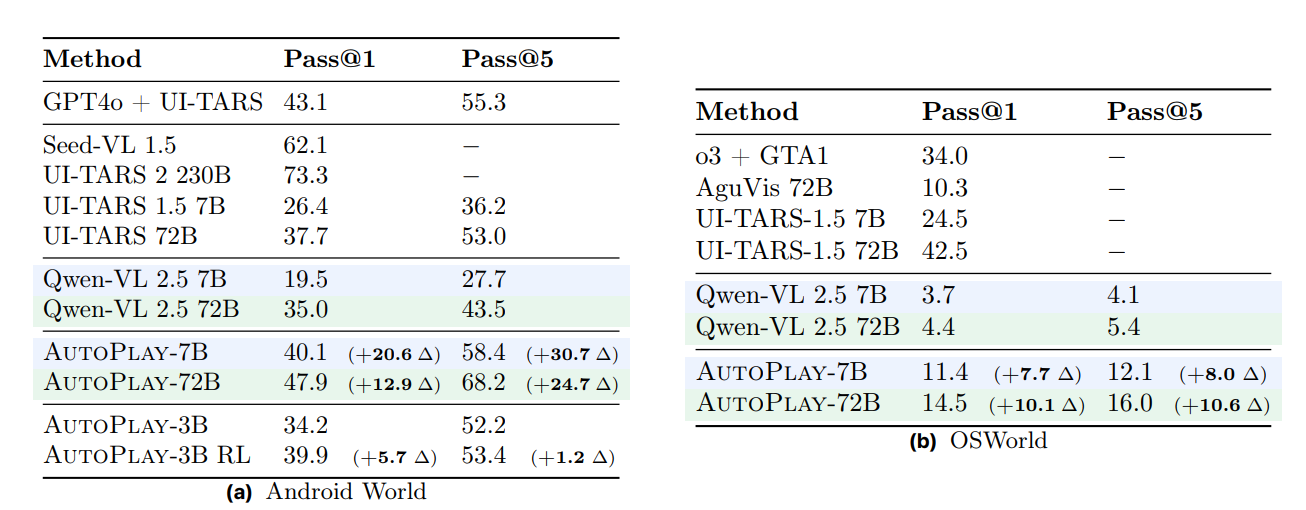
Tab 1. Evaluation results on UI agent benchmarks. Pass@1 and Pass@5 values for AutoPlay models include in parentheses the change relative to the corresponding base model of the same parameter size.
Analysis
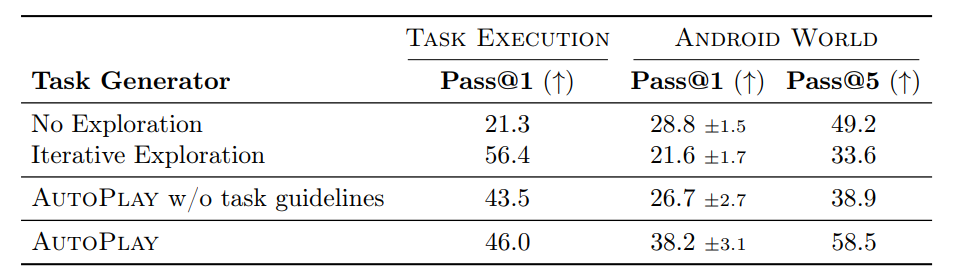
Tab. 2 Ablations. We compare AutoPlay-7B with two baselines that perform lesser exploration, No Exploration and Iterative Exploration, as well as AutoPlay-7B without using task guidelines.
AutoPlay tasks train better agents: To quantify the importance of the environment exploration we compare with two alternative task proposal baselines. The first baseline, No Exploration, unlike AutoPlay, performs no exploration of the domain. Instead, it generates tasks solely from static environment context, such as textual descriptions and application starting screenshots. The second baseline, Iterative Exploration incorporates limited exploration by sequentially executing a series of short-horizon subgoals and summarzing them as tasks, without performing broad exploration of the domain. As a result, it is more constrained than AutoPlay. Tab. 2 shows that agents trained with AutoPlay tasks outperform agents trained with tasks from No Exploration and Iterative Exploration. Agents trained with AutoPlay tasks outperform those trained with No Exploration tasks by 9.4% average success rate. AutoPlay tends to cover a broader range of functionalities in the environment compared to No Exploration. While Iterative Exploration does interact with the environment to generate tasks, AutoPlay tasks train agents that are 16.6% more successful. This is because Iterative Exploration synthesizes long horizon trajectories by stitching easier short horizon subgoals to guide exploration. This consequently leads to less diverse and easier tasks. In contrast, through rounds of long-horizon exploration, AutoPlay generates diverse tasks that provide broad coverage over app functionalities.
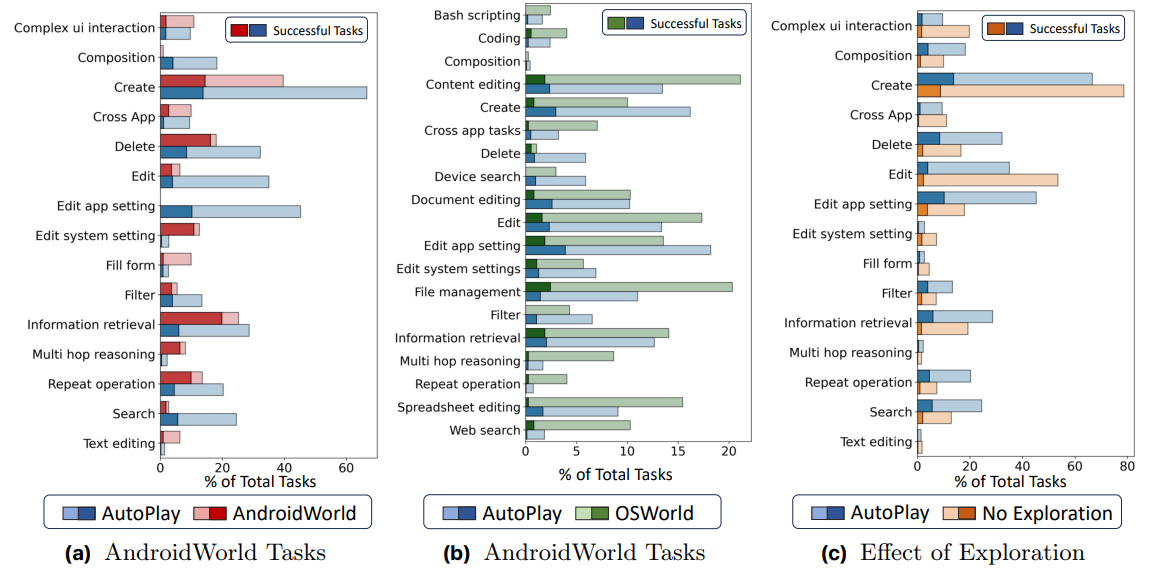
Fig. 3 Task Coverage. Left: For a set of predefined categories, we compare the task distribution across AndroidWorld/OSWorld test tasks and AutoPlay generated tasks in light color. Additionally, we show number of tasks that AutoPlay-7B solves in the benchmark (in blue) vs the number of tasks that get executed to produce training trajectories (in green) using dark colors. Right: For a set of predefined categories, we compare the task distribution across AutoPlay generated tasks and No Exploration generated tasks in light color. Additionally, we show number of tasks that AutoPlay-7B executor solves for both task sets.
Exploration generates more diverse tasks: We compare the task distributions generated by AutoPlay and No Exploration in Fig. 3. The distribution is computed over manually defined task categories that cover a broad range of possible tasks. For example, tasks in the Composition category require combining multiple skills or subtasks to achieve the overall goal (e.g., "Find when John is free and schedule a meeting with him for this week."). Additional details about the task categories are provided in Section E. Although the two distributions exhibit similar trends—categories that are more prevalent under one method tend to be prevalent under the other—the results consistently show lower execution success rates for No Exploration compared to AutoPlay, particularly in categories such as deleting, editing, or retrieving in-app data. This highlights the importance of grounding task generation in exploration.
Paper

@misc{ramrakhya2025scalingsynthetictaskgeneration,
title={Scaling Synthetic Task Generation for Agents via Exploration},
author={Ram Ramrakhya and Andrew Szot and Omar Attia and Yuhao Yang and Anh Nguyen and Bogdan Mazoure and Zhe Gan and Harsh Agrawal and Alexander Toshev},
year={2025},
eprint={2509.25047},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2509.25047},
}