

PIRLNav: Pretraining with Imitation and RL Finetuning for ObjectNav
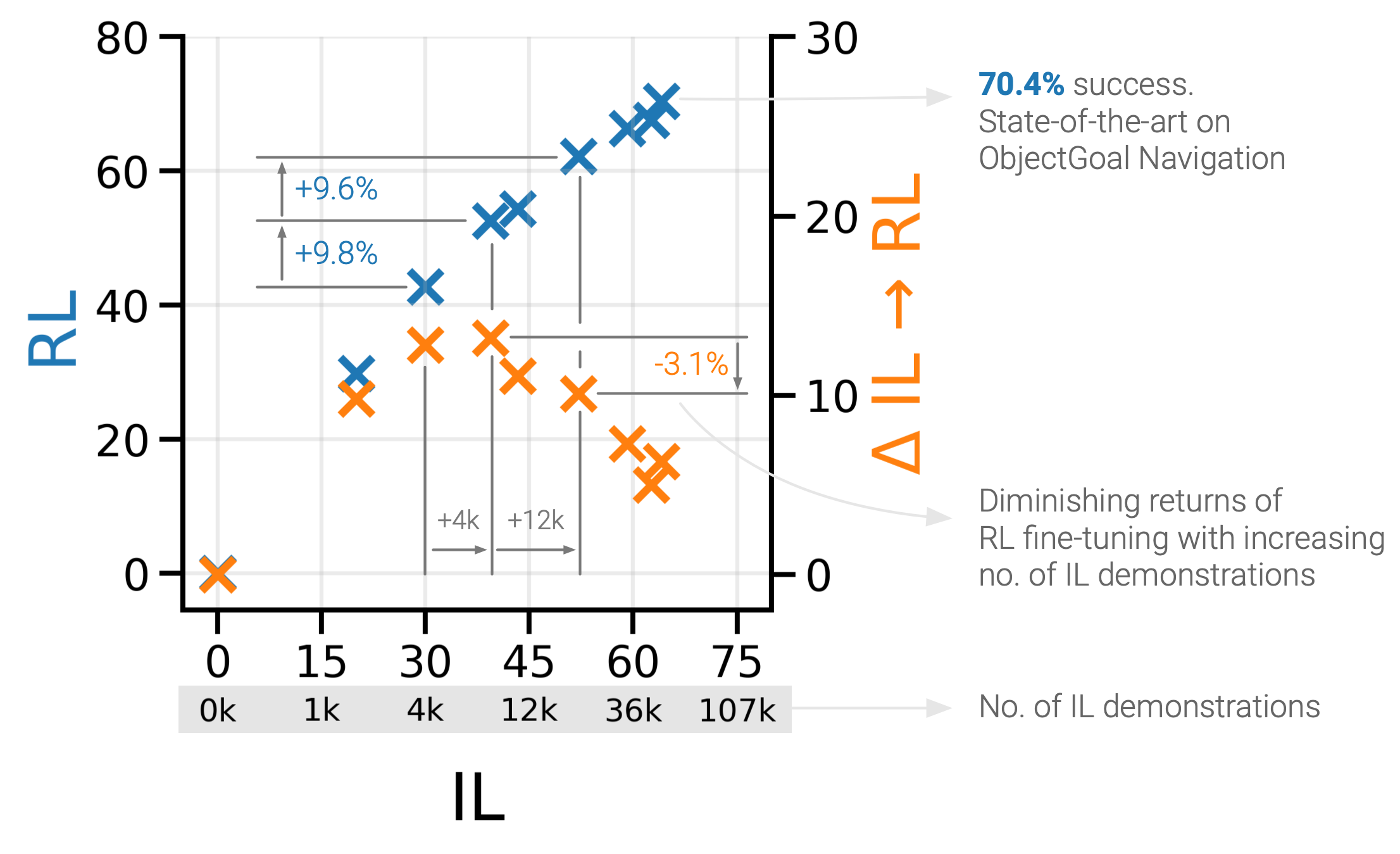
Scaling laws of IL→RL for ObjectNav
We study ObjectGoal Navigation - where a virtual robot situated in a new environment is asked to navigate to an object. Prior work has shown that imitation learning (IL) on a dataset of human demonstrations achieves promising results. However, this has limitations – 1) IL policies generalize poorly to new states, since the training mimics actions not their consequences, and 2) collecting demonstrations is expensive. On the other hand, reinforcement learning (RL) is trivially scalable, but requires careful reward engineering to achieve desirable behavior. We present a two-stage learning scheme for IL pretraining on human demonstrations followed by RL-finetuning. This leads to a PIRLNav policy that advances the state-of-the-art on ObjectNav from 60.0% success rate to 65.0% (+5.0% absolute). Using this IL→RL training recipe, we present a rigorous empirical analysis of design choices. First, we investigate whether human demonstrations can be replaced with ‘free’ (automatically generated) sources of demonstrations, e.g. shortest paths (SP) or task-agnostic frontier exploration (FE) trajectories. We find that IL→RL on human demonstrations outperforms IL→RL on SP and FE trajectories, even when controlled for the same IL-pretraining success on TRAIN, and even on a subset of VAL episodes where IL-pretraining success favors the SP or FE policies. Next, we study how RL-finetuning performance scales with the size of the IL pretraining dataset. We find that as we increase the size of the IL-pretraining dataset and get to high IL accuracies, the improvements from RL-finetuning are smaller, and that 90% of the performance of our best IL→RL policy can be achieved with less than half the number of IL demonstrations. Finally, we analyze failure modes of our ObjectNav policies, and present guidelines for further improving them.
Read more in the paper.
Short Presentation
Successful Examples




Failure Modes




Paper

@inproceedings{ramrakhya2023pirlnav,
title={PIRLNav: Pretraining with Imitation and RL Finetuning for ObjectNav},
author={Ram Ramrakhya and Dhruv Batra and Erik Wijmans and Abhishek Das},
booktitle={CVPR},
year={2023},
}
Code and Data
People




Acknowledgements
We thank Karmesh Yadav for providing model weights for OVRL, and Theophile Gervet for answering questions related to the frontier exploration codebase used to generate demonstrations. The Georgia Tech effort was supported in part by NSF, ONR YIP, and ARO PECASE. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of the U.S. Government, or any sponsor.