

Grounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning

Ask-To-Act. In this task, the user requests a specific green cup but, instead of describing it in detail, asks the agent, "Bring the cup and place it on coffee table". Since the user's intent is unclear, an agent must ask a minimum number of clarification questions to disambiguate the requested object (e.g. "Are you looking for a red cup?" or "Is it on the kitchen counter?"). We consider under-specified single and multi-object rearrangement tasks that involve inquiring about user preferences and resolving different types of ambiguities, about object attributes, spatial relationships, object size, placement location, or combinations of the four.
Abstract
Embodied agents operating in household environments must interpret ambiguous and under-specified human instructions. A capable household robot should recognize ambiguity and ask relevant clarification questions to infer the user intent accurately, leading to more effective task execution. To study this problem, we introduce the Ask-to-Act task, where an embodied agent is tasked with a single or multi-object rearrangement task using an under-specified instruction in a home environment. The agent must strategically ask minimal, yet relevant, clarification questions to resolve ambiguity while navigating under partial observability. To address this challenge, we propose a novel approach that fine-tunes multi-modal large language models (MLLMs) as vision-language-action (VLA) policies using online reinforcement learning (RL) with LLM-generated rewards. Our method eliminates the need for large-scale human demonstrations or manually engineered rewards for training such agents. We benchmark against strong zero-shot baselines including GPT-4o as well as supervised fine-tuned MLLMs on our task. Our results show that our RL-finetuned MLLM outperforms all baselines by a significant margin ($10.4$-$16.5\%$), generalizing well to novel scenes and tasks. To the best of our knowledge, this is the first demonstration of adapting MLLMs as VLA agents that can act and ask for help using LLM-generated rewards with online RL.
Read more in the paper.
Approach
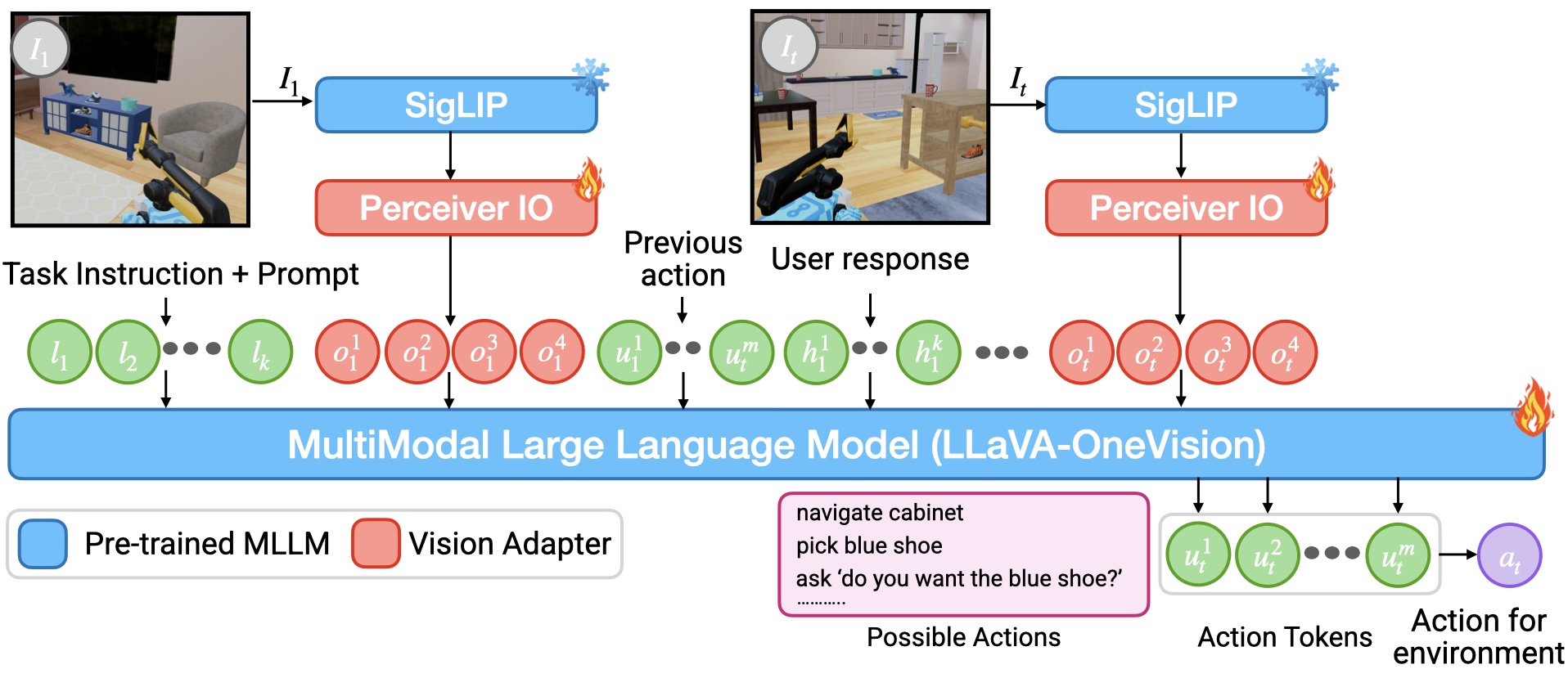
Fig. 1. MLLM Policy Architecture. The policy takes as input a task instruction, sequence of past observations, actions, user response to questions asked and outputs a high-level action (i.e. skill) or a question in natural language.
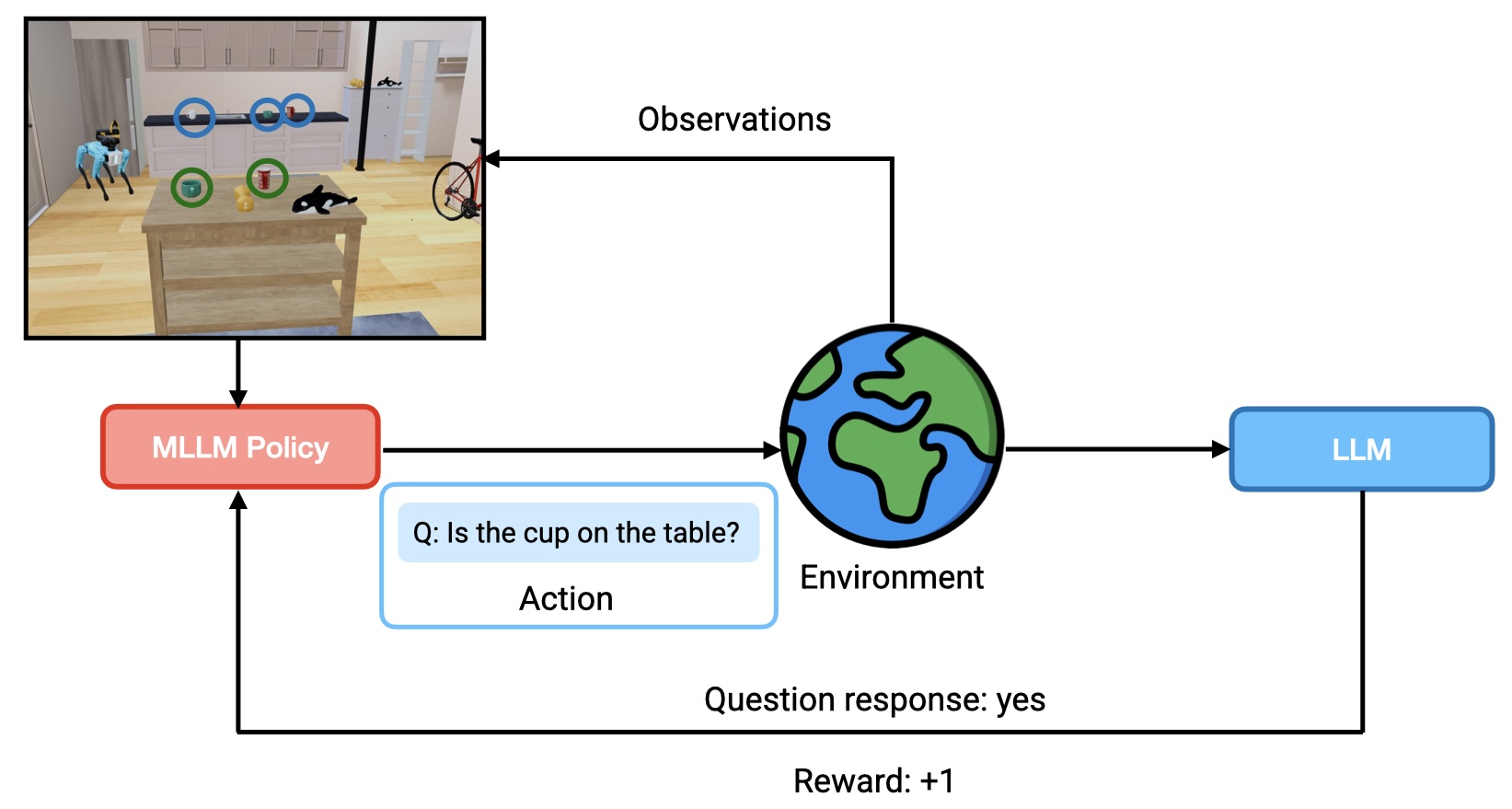
Fig 2. RL training loop.
Our key idea is to bootstrap the learning signal required for training embodied agents capable of interacting and asking in an end-to-end manner by leveraging an LLM's contextual commonsense and deductive reasoning ability to resolve ambiguity. We accomplish this by adapting a multimodal large language model (MLLM) into a vision-language-action (VLA) model using large-scale RL with reward signal generated using an LLM with access to privileged information from the simulator. To distill reasoning ability required for resolving ambiguity into this VLA model, we propose to use per-step rewards generated using an LLM that evaluates both the actions taken and natural language question asked by the agent in context of the task. Through our experiments, we show that LLMs are highly effective at generating per-step rewards for such tasks that require interacting with environment and asking questions to resolve ambiguity, when provided with the right representation of task and environment in text - information that can be easily curated at training time using privileged simulator state. This framework enables us to adapt MLLMs into VLA models that can interact with the environment and resolve ambiguity by asking questions without expensive human demonstrations or manually engineered rewards.
Results
We show evaluation results of our approach LLaVA-OV RL against zero-shot baselines leveraging GPT-4o with tool use and with SoM + ReAct prompting, and LLaVA-OV model trained using synthetically generated SFT data. Our method (row 6) outperforms all baselines by a significant margin, on success rate by +41.6% on Unseen scenes split and by +31.1% on Unseen tasks split.
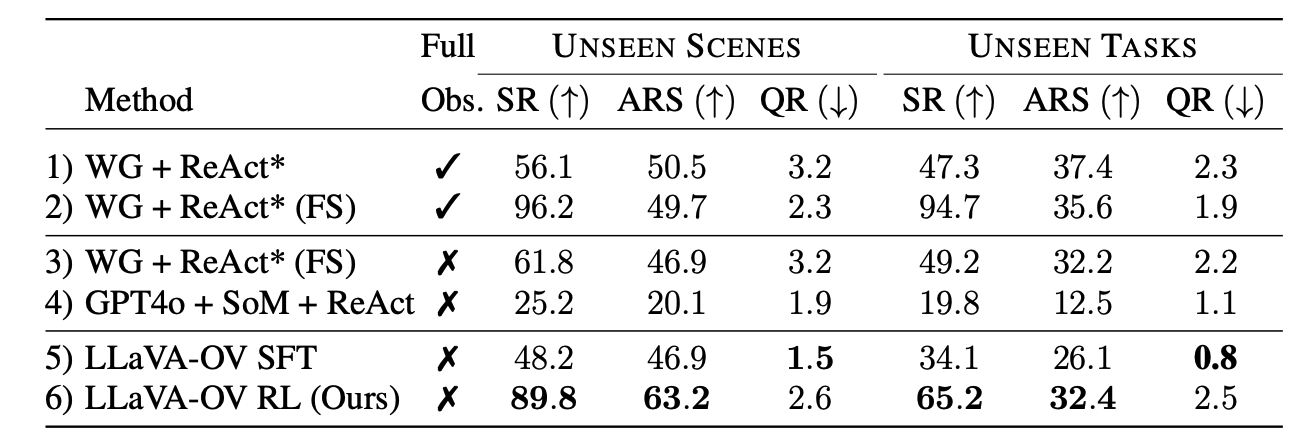
Tab 1. Evaluation of all methods on Unseen Scenes and Unseen Tasks evaluation splits of Ask-To-Act task. FS denotes few-shot examples, * denotes access to privileged information, Full Obs. stands for full observability.
Analysis
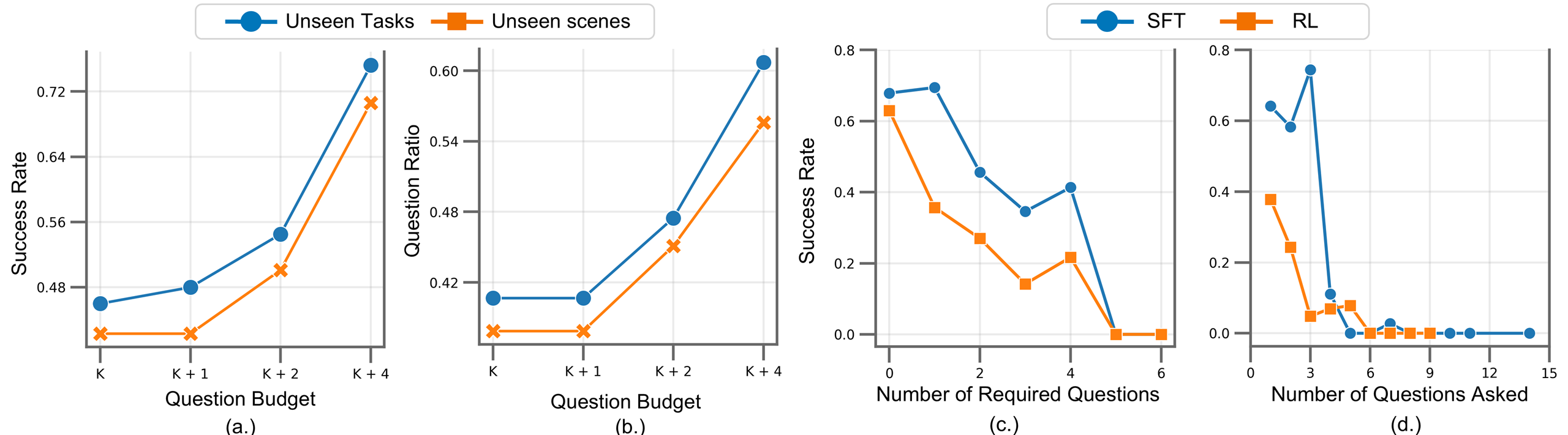
Fig. 3 Analysis. (a.) Task Performance vs. Budget of Questions. Evaluation performance of policies trained under different budget of questions vs task Success Rate and Ambiguity Resolution Efficiency score. (c.) Success Rate vs. Number of Required and Asked Questions. Evaluation performance of SFT and RL trained policies vs number of required and total questions asked by the agent.
Training policies under variable budget. A desired skill for an embodied agent that can ask questions is to adhere to user's preferences about how often they would like a robot to ask clarification questions. Some would prefer an agent ask as few questions as possible for better user. In contrast, some users would be fine with an agent asking as many questions as it would like to ensure task success rates are higher. Motivated by this, we train multiple MLLM policies using RL with LLM generated rewards with a variable upperbound on maximum number of questions an agent can ask. Specifically, we train policies with a budget of B ∈ {K, K + 1, K + 2, K + 4} questions, where K is defined as minimum required question for a task in Ask-To-Act dataset. In this setting, an agent can ask at most B questions in a single episode (either relevant or irrelevant) without incurring any penalties. Note, for this experiment B is either equal to K i.e. ask as close to minimum required questions as possible or can be quite high K + 4 where an agent can ask as many as 4 extra questions than minimum required in each episode without incurring any penalties. Additionally, the agent will only be rewarded for relevant questions from all questions it asked. We only penalize the agent for each question asked after exceeding the question budget B. Fig. 3 shows success rates of various policies trained with different budgets under the reward setting described in Eq. (1). As shown in Fig. 3 (a.), as we increase the number of questions the agent can ask, the success rates increase; however, there is a clear tradeoff between increase in success rates and question ratio (i.e. asked questions to minimum required), see Fig. 3 (b.).
Qualitative Examples
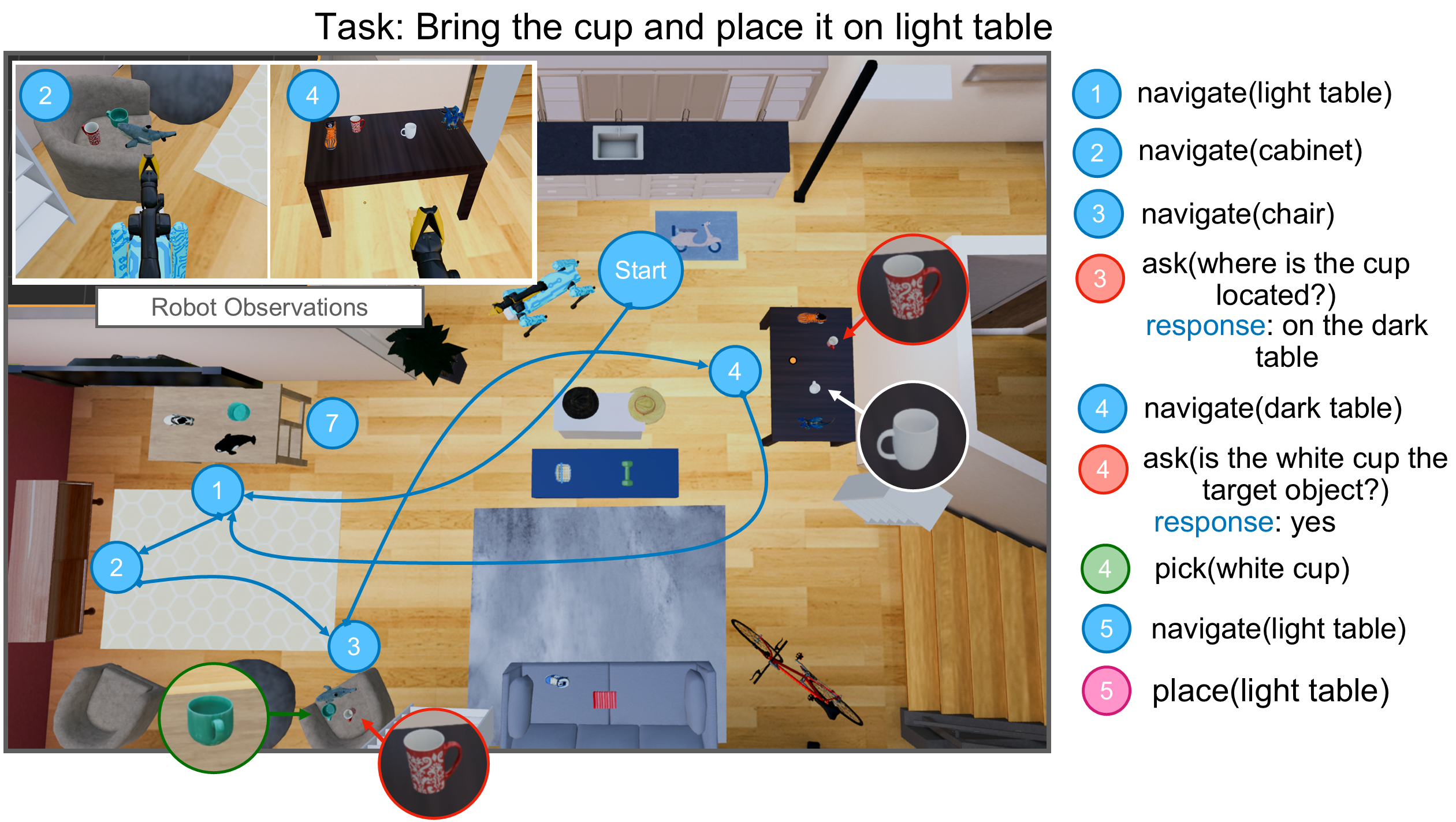
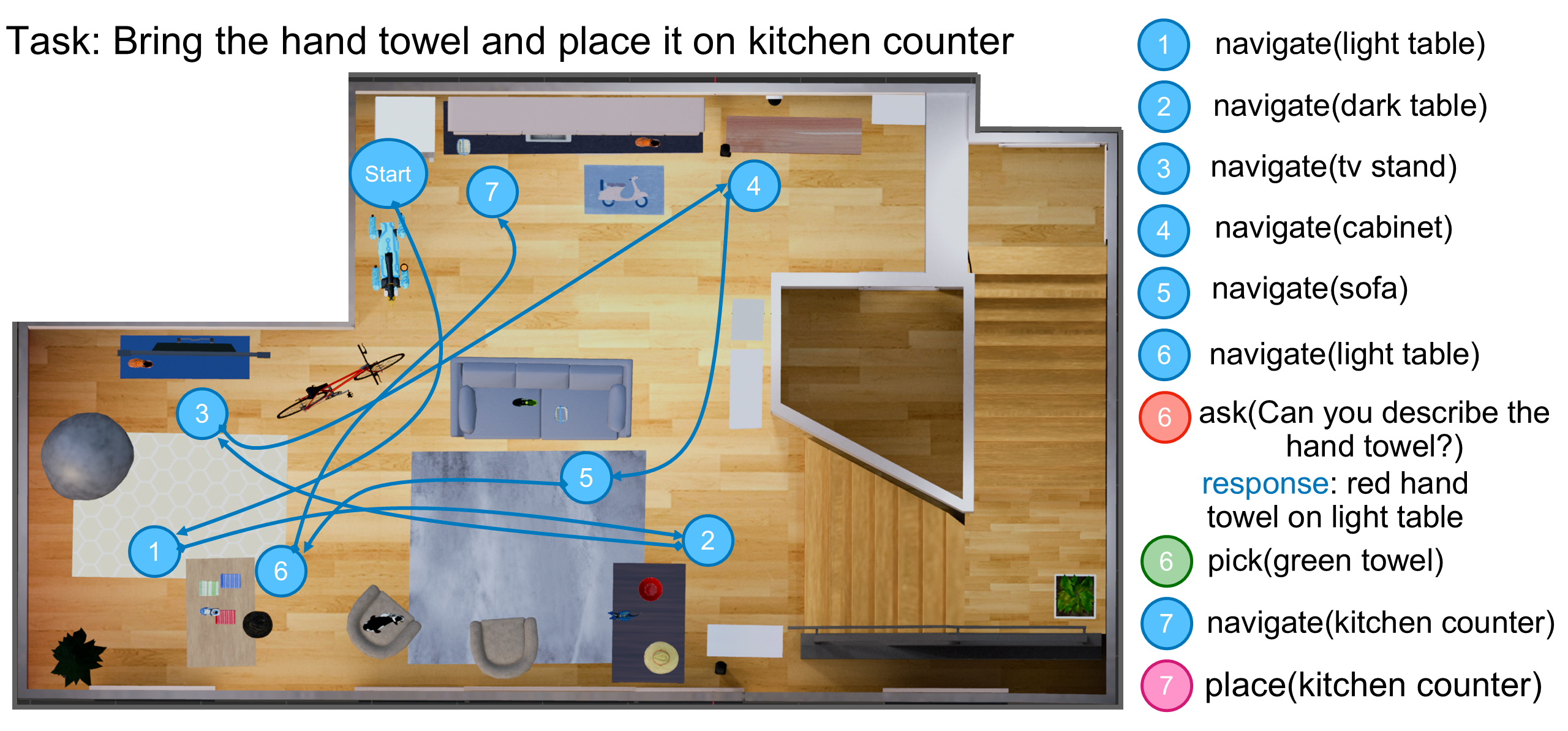
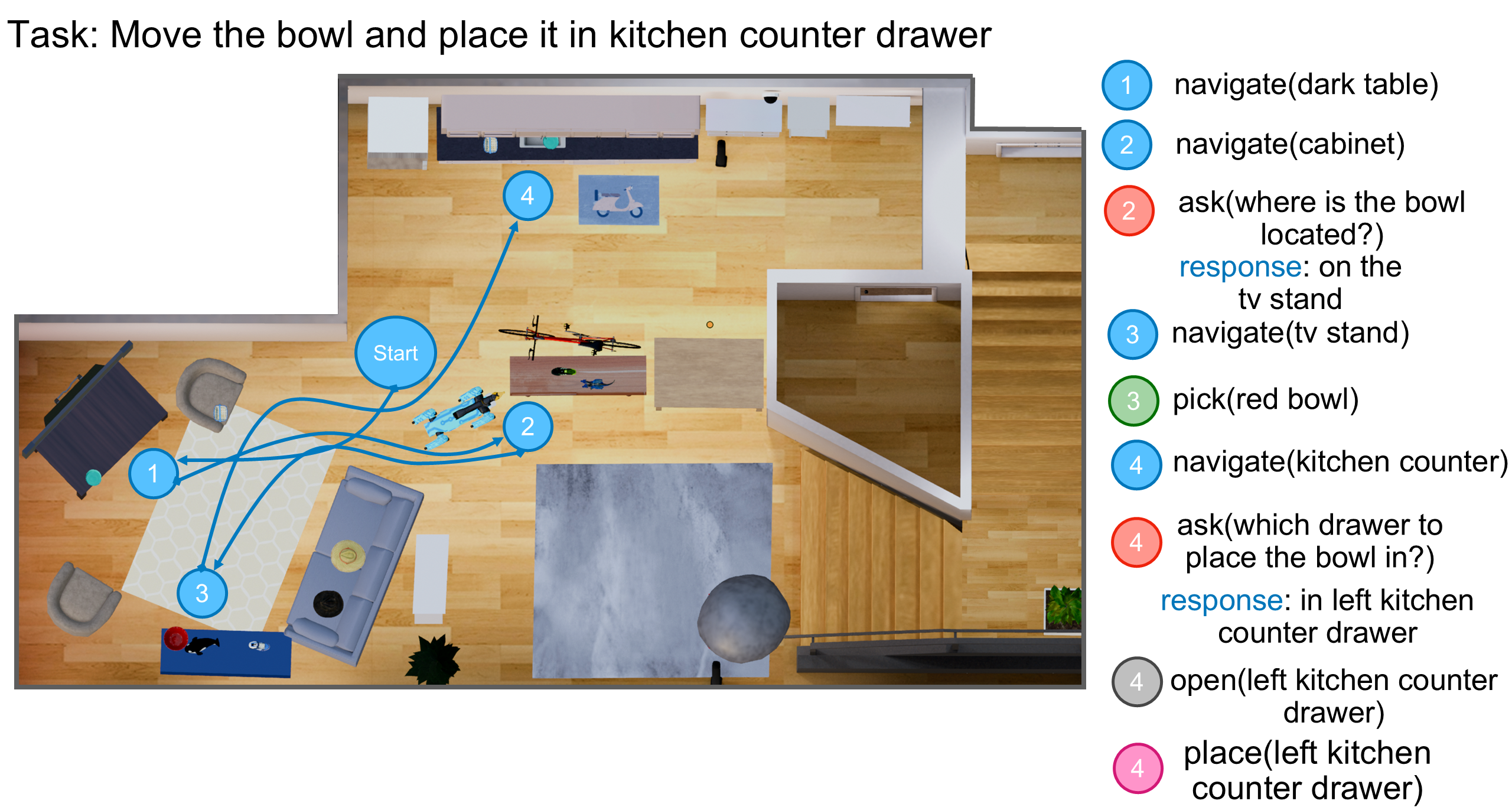
Qualitative example of successful trajectories of our method on three evaluation episode from Unseen Tasks split.
Paper

@misc{ramrakhya2025groundingmultimodalllmsembodied,
title={Grounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning},
author={Ram Ramrakhya and Matthew Chang and Xavier Puig and Ruta Desai and Zsolt Kira and Roozbeh Mottaghi},
year={2025},
eprint={2504.00907},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.00907},
}
People





